
Dunbar's Number is Quadratic
Social Media's Cybernetic Problems (Part I)
Ours is a brand new world of allatonceness. “Time” has ceased. “Space” has vanished. We now live in a global village…a simultaneous happening. We are back in acoustic space. We have begun again to structure the primordial feelings, the tribal emotions from which a few centuries of literacy divorced us.
Marshall McLuhan / Quentin Fiore. The Medium is the Massage (1967, p. 63)
The Pre-Global Village
Dunbar's number refers to the claim that people can only manage relationships with around n people. (Most commonly, n is a very hand-wavy 150.) It's one of those ideas that made the leap from academia to popular science and then to cocktail parties. Consequently, I cite it, quote it, and talk about it, as well. But, I'm not a big fan of Dunbar's number for a few reasons.
First, either I continue to misunderstand it or most other people do, and I'm pretty sure it's the latter. Managing relationships with n people does not entail "knowing" 150 people in the dyadic sense of having had sufficient experience with them to recall who they are. That's not how human sociality works. Managing relationships with n people means something closer to: you both have some experience with them and also understand how they socially relate to everyone else. That is, you know 150 people when you can competently predict how any two of them would interact in paired-off social circumstances without you. In the narrow context of anthropology skewed towards the lower end of socio-complexity, the difference is hard to see. For bands or tribes bound by geography, resource scarcity, and compressive kinship grammars, knowing 150 people and understanding how they relate to one another comes close to meaning the same thing. But as we move towards increased socio-complexity, the distinction becomes critical: Dunbar’s number is a statement about inter-relationship comprehension with upper-bounds quadratic in n, not linear.

This restatement allows me to introduce the second, much stronger reason I don't like Dunbar’s number, at least in common retellings. Extrapolating with data from other primates, Dunbar himself theorized that the binding constraint was neurological.[1] That — impressive as our brains may be — we can't seem to juggle social relationships with more than 150 people. Expanding that to the upper-bound of 22,500 possible inter-relationships, (150²), it sure does seem challenging! But, as the band/tribe example demonstrated — and as Herbert Simon emphasized endlessly — the environment itself shapes problem-solving considerably, and we are remarkably proficient at shaping ours. Thus, I don’t think cognition is what binds; I think it’s mostly environmentally-shaped social time.
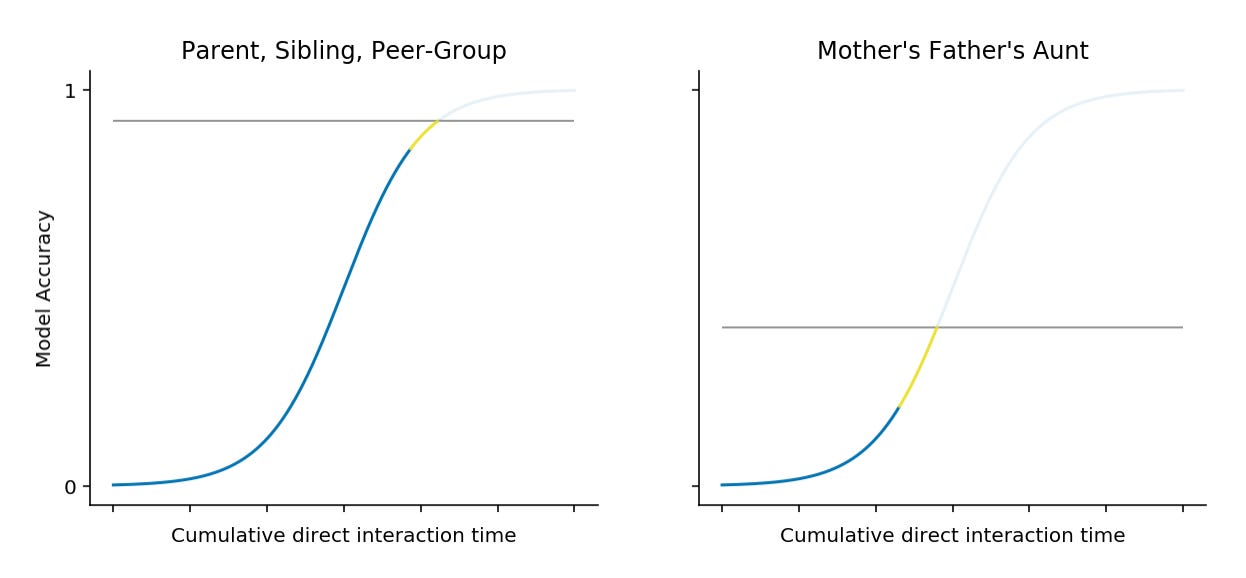
At the level of a band or tribe — where geography, kinship, and resource scarcity compel durable proximity — it seems reasonable to believe you could accumulate direct experiences with 150 people that would allow you to induce at least some mental model for them all. The quality of each model varies with experiential time, which is some function of social proximity. You'll have an excellent model for your parents or siblings or peer-group; you’ll have a worse model of your mother's father's aunt.

With the computer scientist's cap on, the question becomes a familiar one: if it is time that binds, are there more efficient (sampling) algorithms? Nature and human experience answer in the affirmative: we gossip.[2] Talk is cheap in the sense that it is not expensive, not in the sense that it is valueless. It takes less time to gossip than to observe or participate in all the covered interactions. At the level of band or tribe (proximity-constrained and with kinship grammars to compress the inter-relationship space), we would reasonably expect to have mental models for both the gossiper and subject of gossip. Consequently, we can evaluate the gossipers claim; judge its veracity; then, update our expectations of both accordingly. Given the same time constraints, an allocation to gossip can boost model performance.
Further boosting comes from the particular social topologies we readily forge — in particular cliques. Each member of a clique has semi-regular direct interactions with every other member, allowing them all to induce good models of mutual behavior. They also gossip about each other frequently. In this particular configuration, there is the happy coincidence of accessible good models for all the implicated parties for the purpose of evaluation and judgement. This makes deception both more difficult to achieve and more costly — good models detect the attempted exploit and that detection may quickly propagate within the group of people the deceiver interacts with most. Thus, cliques are remarkably efficient in social and information-theoretic terms.[3] For the same amount of effort, you can produce a greater number of high quality mental models.

This trusted dense core — along with progressively less dense ones that Dunbar did talk about — allows us to deliberate over more far-flung spaces in our social neighborhood. The cost? Errors become correlated. Social expectations become the product of ensembles. At low-levels of socio-complexity, this isn't pathological. The errors are already implicitly conditioned on interaction frequencies and there is still considerable shared reality so, in some sense, the errors are structurally minimized. But, at higher-levels of socio-complexity, things fragment. Ensemble expectations become JIT category factories, and the consequent space of inter-relationship schemes explodes. Sometimes, calamitously.
The Twitter-Scale Global Village
Armed with this conceptual framework, we can now shift our attention to social media. The environment is dramatically different. Time still binds there…but "there" is a different kind of there. Geographical coincidence no longer limits the set of potential relationships. People can transcend many of their traditional and local circumstances. This is, of course, the most celebrated aspects of social media — one that I continue to delight in. But, it also moves us closer to the asymptotic, quadratic upper-bound of complexity for inter-relationships in ways we never have before.
To get a sense of our new scale, the following graph shows the empirical cumulative distribution functions for twitter friend and mutual relationships over a sample of 33,292 users.[4] Here, ‘friend’ refers to someone the ego follows and ‘mutual’ refers the the case where the person followed also follows the ego. (The curious notch in the Friends CDF is a social artifact of twitter’s subscription rules that allows a maximum of 5,000 friends under promiscuous-growth-limiting conditions. The shaded portion portrays 95% of the mass. The vertical line is the median.)

The median number of mutuals is 244 which is well within the plausible range for Dunbar’s number. The median number of friends — those we preferentially observe— is 798. In both cases, the distributions are far from Gaussian. To a large degree, the beefy right tails are an environmental effect. Friends and follows don't decay from disuse on twitter as they would in a “real” (non-digitized representation) of a relationship. This inflates friend and mutual statistics in misleading ways, especially if algorithmic mediation winnows presentation, as it almost certainly does.[5] But, the inescapable conclusion is that, without geographical confinement — and, with a communication channel that approaches the lower-limit of legible expression — we're no longer in the anthropologically tame world of bands and tribes.
Of course, there are familiar social regularities. Cliques continue to form as they always do. You don’t need to fire up Jupyter notebook to see that. Even limited to avatars and ambient intimacy, we're remarkably good at detecting cliques. It's a familiar twitter experience: this person belongs with that one and some others — not in a stereotypical way, but in a who-sits-together-in-the-cafeteria one. We seek the strong force of social density.[6] But, the rest of the interaction space has unfamiliar and sometimes uncanny sparsity. In my conception of Dunbar’s number, I used 150² = 22,500 as the upper-bound alternative for people who exist in an environment where fully-connected graphs were plausible. (That is, everyone does indeed "know" everyone, in some not-entirely indirect way.) Social media is not that environment. As the following graph of friends-of-friends and mutuals-of-mutuals shows, it’s much wilder.

The median friends-of-friends and mutuals-of-mutuals are 209,043 and 66,787, respectively. These are big numbers (and they are both gross UNDERESTIMATES given API limitations).[7] Clearly, the frontier set of who you or someone you know might interact with in an observable way is huge. Of course, you could say the same thing about any “IRL” city. Just because they are accessible does not mean they are accessed. Except, they are — and with regularity. The following graph shows the proportion of interactions by relationships and interaction types. With the sample I have, it’s not possible (yet) to properly partition friends-of-friends (mutuals-of-mutuals) from outside of friends-of-friends (mutuals-of-mutuals). Consequently, “outside” here merely means not in the friend or mutual set.


Unsurprisingly, most interactions take place between friends (i.e. people the ego follows) and around a third of interactions take place between mutuals. But, an impressive amount takes place outside these relationships. Your friends and mutuals do not form anything like a blanket for interactions you only occasionally escape. And, rightfully so — ambient discovery couldn't work so wonderfully well if they did! However, this also presents a critical problem. There is no way to accrete sufficient interactions and observations with something on the order of 60,000 people (in the dramatic underestimate). Even if you could, cognition really does bind here.
But, it's worse than that because the latent space we're intrinsically trying to navigate is the quadratic inter-relational one. In search of lacking and needed structure, our remarkable pattern-matching machinery gets to work manufacturing cues from scant material. To some degree, that’s what culture affords. On twitter, it means we create meaning from things like "pronouns in bio" or American flags in a display name or the hashtags in someone’s tweets or even the vocabulary someone uses. These cues provide a means to aggregate experiences, transcending experiential sparsity in a way that affords stable expectations. Thus, when we're confronted with contexts that have limited, ambiguous, noisy, and error-prone available information — something that happens with high frequency on twitter — cues offer a strong and readily available signal for integration. Absent the necessarily experience, the resulting mixture allow us to construct “good” models in a better-than-chance predictive sense.
Unfortunately, the social cues end up dominating the accessible information. You find yourself updating expectations in response to synthesized experience over what is often not much more than noise. (You notice this most on the knife’s edge — "I think I like this post but let me first check the profile description and a few other tweets to make sure.") The trouble is that the resulting judgment back-propagates over both our social and asocial beliefs (i.e. knowledge or something like it). Concurrently, by something like Hebbian logic, these ensemble-manufactured social cues end up wiring your interaction networks — providing the missing relational structure through something like a self-fulfilling social prophecy. Thus, the chronically-correlated errors have much more pathological effects. Social beliefs leak far too much information into our (presumptively) asocial ones.
Tomorrowland
Recapitulating, what binds us now isn't that we can suddenly connect to n people, where n continues to approach the full population of the world. What binds is our ability to navigate the quadratic inter-relational space. We may aspire to treat other people as individuals but, in practice, what we get is a proliferation of categories with attached expectations that condition perception and behavior. This begs the big question: do we have sufficient means of grounding to resist the decoherence of beliefs and the reification of cues induced by these entropic contexts? Or, do they occur with such pinned frequency that we can't recover — such that the errors can't correct, and instead they invade and degrade surrounding knowledge?
I don't know.
It's an unanswered question. More than that, I think it's an analytically intractable one. Not only is social media a remarkably complex system in its own right, but it's not an isolated one and the world is fantastically large and messy. Personally, I’m irrevocably optimistic. History repeatedly documents the death knells that never came. Writing destroys the mind! Books destroy the mind! Radio destroys the mind! TV destroys the mind! The world wide web destroys the mind! Social media destroys the mind! Except they didn't and probably don't. What new mediums do destroy is the primacy of older ones.
Along the same lines, there is nothing magically natural about the social configurations of bands and tribes. Mostly, they ofter us hints as to evolutionary pressures inherent in our species’ once-upon-a-time cradle. The same applies to the world as we imagine it was before social media — it isn’t privileged. Homo sapiens sapiens is nothing if not adaptive. We shape our environment; our environment shapes us, over and over again, recursively and with no end. This is more of that. What we're building / growing / evolving now will change the ways in which we relate to one another. They already have; they still have to. The architecture is fundamentally different: what we individually and collectively can perceive and achieve will be, too. It need not be harmful and it is not unnatural—it's just next.
None of this is to say we're there yet…wherever there is. Criticism remains, as always, important — it’s one of the basic corrective mechanisms we have to flop about the space of shared possibilities somewhat reasonably. It isn't merely valid — it's utterly necessary. There were, are, and will continue to be problems, many of them serious. We don’t yet know which structures are reliably bad and generate robust harm. However, we can recognize that current designs still fail to implement the sensing tools we need to perceive and the actuators we need to act in the new socio-cultural space. They mix dyadic relationships and experiences with social and cultural ones in ways that durably frustrate our cognition. More than that, limited APIs aside, we're mostly subjects of centrally-managed architectures that frustrate design innovation and evolution. We're governed by entities trying govern an intractable space at speeds that can't even keep up with last year's 0-days. The opportunities for and inherent to a new ecosystem are profound.
But, I think everyone (myself included) needs to spend sufficient time zoomed out far enough to see the full field. Already, we spend time online to entertain ourselves, to seek validation, to mitigate social isolation, to learn, to discover opportunities, to transact, and to deliberate. There isn't one mode. It's not one thing. It's not an isolated or meaningless playground, as some of the most confused critics claim. It's closer to a new kind of metropolis or nation.
Or what eventually competes with them…
…past human performances are no guarantee of future realizations.
After finishing a Ph.D. investigating belief system expression and discovery through simulation, I started working on a social immune system for twitter leveraging their API. Eventually, I realized that trying to build an elaborate sandcastle on someone else’s private beach isn’t the smartest of plays. Now, I’m building something else. If you are in this space — and especially if you foster romantic notions about the power and promise of decentralizing computer-mediated communication — please reach out. I want to hear from you.
Thanks to my wife and Danny Horowitz for reviewing drafts.
Notes:
I’ve taken considerable liberties in relaying the anthropological story and literature because this isn’t an academic post and I’m not writing a lit review. I’m also deliberately using terminology that frustrates ease-of-concept recognition for both academics and people familiar with other pop-sci terminology (e.g. ‘intersubjective’), hoping to constrain attention to a more narrow band of discussion.
Here is an example of where I’m taking some poetic license. Dunbar talks about the relationship between grooming and trust formation quite explicitly. He even theorized how that could evolve into language (and was largely criticized for the claim). But the academic chain-of-evidence here obscures the point I’m trying to make. (Plus I haven’t read him in a decade.)
If you haven’t read Robert Axelrod’s, The Evolution of Cooperation, I strongly encourage you to do so. I’m admittedly biased (my dissertation cites his as foundational work), but it’s such an elegant and beautiful demonstration of things that are otherwise hard to reason about.
This is a weird and biased sample. I drew it using snowball sampling with both Paul Graham and myself as the seeds. Except, frontier expansion followed all friend relationships in breadth-first order. That is, it sampled all the people Paul Graham followed; then the people they followed. (And the same starting for me). At the time of writing, n=33,292.
Admittedly, snowball sampling has some serious problems in most cases. In this one, it over-samples from the top-end of active users. If you took a much larger sample of friends and followers via the tweet sampling endpoints (which wouldn’t get you mutuals), you’ll see lower medians because it mixes casual and active users (and, without correction, retains those with no friends and followers). Since I believe the information environment for everyone will increasingly resemble the world the latter now lives in, I don't foresee any qualitative deviation from what I'm trying to broadly show here associated with my sampling method.
I have to look through twitter’s new restrictions on sharing for academic purposes. This is graph stuff (their moat), which they care about a bit more than just tweet IDs. But, eventually, I hope this analysis, at least, will find a home on falsifiable.com…once I launch that.I have no good means of testing it, but I’m pretty confident that people with high friend and mutual counts tend to rely on algorithmic curation, careful list hygiene, or alternative interfaces like tweetdeck. You can test for the last case with the source field of a tweet entities, but I haven’t done so.
There’s a connection to the efficient coding hypothesis here that I keep trying to make unsuccessfully. Maybe you can find it though.
Snowball sampling along the frontier of friends in full breadth-first order has exponential growth. From each seed, you follow ⟨𝑘⟩ paths; then, for each sampled node, you follow ⟨𝑘⟩ more; then, for each of those, you follow ⟨𝑘⟩ more. Given the twitter's API limits, this makes friend-of-friend work...difficult. (Although, again, you could get just the friend distribution by collecting user entities.) At the time of writing, approximately 92% of relationships are missing from this analysis. Hence, I lump friends-of-friends (and mutuals-of-mutuals) together as "outside" when they would be much more interesting once partitioned.
The problem is fun to think about because this "missingness" statistic is related to the structure of the graph. For example, if you have a fully-connected component, then you may have 9 friends and they all have 9 friends but the entire population is 10 people, making sampling linear not quadratic at depth one. Twitter is not like that though — it’s much more sprawling. Until some unreachable (given API limits) point, the expanding frontier will always produce an outcome so that most of the friend-of-friend/mutual-of-mutual set is missing. There are better sampling methods and means of correction, but this sample wasn't even meant for this particular analysis, and the corrections aren't trivial.
Secondary question on Dunbar: What is your stance on the 5-15-50-150 "Dunbar's Circle"? Are they effective identification of empathy size, size of effective teamwork, and so on? Would the Quadratic scaling theory apply to this layering as well?
Very interesting to think through. One note though; Grammatical error: "Nature and human experience answers in the affirmative: we gossip." The "and" makes it a compound subject, requiring the plural "answer" rather than the singular "answers."